FilterForward简介(边缘过滤方法)
随着摄像机部署的不断增加,处理大量实时数据的需求给广域网基础设施带来了压力。当每个摄像头的带宽有限时,交通监控和行人跟踪等应用程序将高质量视频流卸载到数据中心是不可行的。本文介绍了FilterForward,它是一个新的边缘与云的协作系统,它通过安装轻量级的边缘过滤器(只对相关的视频帧进行反向传输),使基于数据中心的应用程序能够处理来自数千个摄像头的内容。
Scaling Video Analytics on Constrained Edge Nodes
作者:Christopher Canel * 1,Thomas Kim * 1,Giulio Zhou 1 Conglong Li 1, Hyeontaek Lim 1, David G. Andersen 1, Michael Kaminsky 2 ,Subramanya R. Dulloor 3,1
摘要
随着摄像机部署的不断增加,处理大量实时数据的需求给广域网基础设施带来了压力。当每个摄像头的带宽有限时,交通监控和行人跟踪等应用程序将高质量视频流卸载到数据中心是不可行的。本文介绍了FilterForward,它是一个新的边缘与云的协作系统,它通过安装轻量级的边缘过滤器(只对相关的视频帧进行反向传输),使基于数据中心的应用程序能够处理来自数千个摄像头的内容。FilterForward为每个应用程序引入了快速而富有表现力的“微分类器”,它们共享计算,以便在计算受限的边缘节点上同时检测几十个事件。只有匹配的事件被传输到云。对两个真实世界的摄像机数据集的评估表明,FilterForward减少了一个数量级的带宽使用,同时提高了具有挑战性的视频内容的计算效率和事件检测精度。
本文是(Canel et al.,2019)的扩展版。
*Equal contribution;1Computer Science Department, School of Computer Science, Carnegie
Mellon University, Pittsburgh,Pennsylvania, USA ;2Intel Labs, Pittsburgh, Pennsylvania, USA;
3ThoughtSpot, Palo Alto, California, USA. Correspondence to: Christopher Canel
ccanel@cmu.edu.
1 Introduction(简介)
在城市地区,摄像机的部署无处不在:商场、办公室、家庭、街道、汽车和人们。2017年,全球购买了近1亿个联网监控摄像头(IHS)。基于机器学习的实时数据流分析,如交通监控、客户跟踪和事件检测,有望在效率和安全性方面取得突破。然而,在一个现代城市中,成千上万的不间断摄像机产生每秒数百gb的数据,这会造成共享的网络基础设施负荷过大。这一问题在大都会中心(FCC)以外地区,对于无线和外围连接节点来说更严重,因为他们经常有更多的约束网络(Google无线网络;ITU /联合国教科文组织宽带可持续发展委员会,2017)。此外,上传视频的不可行性与视频分析应用的日趋复杂所冲突,而这种视频分析应用恰好设计运行在数据中心。本文讨论了如何克服这一网络瓶颈,将大量数据从分布式相机部署实时转移到数据中心进行进一步处理。
由于目前部署相机的扩展和相机分辨率的提高,这些需求需要一种基于边缘的过滤方法,这种方法节省了有限的带宽。因此,我们提出FilterForward,它是一个系统,提供了边缘计算和以数据中心为中心的广域视频处理方法。通过使用相机配置的边缘计算资源,FilterForward标识与数据中心应用程序最相关的视频序列(“过滤”)并仅卸载该数据以供进一步分析(“转发”)。通过这种方式,FilterForward能够实现在数据中心中运行程序的近乎实时处理,同时限制了低带宽广域网链路的使用。
FilterForward是为满足两个关键假设的场景而设计的,这两个假设对于某些应用程序(当然不是所有应用程序)是适用的。首先,相关事件很少发生。只传输相关数据可以节省带宽。其次,数据中心应用程序需要高质量的视频数据来完成它们的任务。这排除了诸如严重压缩流或降低其空间(帧尺寸)或时间(帧频率)分辨率等解决方案。
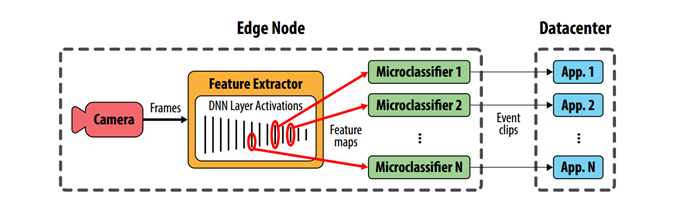
在FilterForward模型中,数据中心应用程序表示对特定类型的可视内容感兴趣(例如,“向我发送包含dogs的序列”)。每个应用程序在边缘安装一组称为微分类器(MCs)的小型神经网络,这些神经网络对每个传入的帧执行二进制分类,以确定是否发生了感兴趣的状态。通常,一个有趣的状态是根据某个对象的存在来描述的。每个MC都由一个应用程序开发人员进行过离线训练。在运行时,对框架级分类结果进行平滑处理以确定事件(当服务器感兴趣的时候被称为事件)的起始点和结束点。事件被重新编码并流到数据中心。
FilterForward扩展到多个独立的应用程序(例如,“找到狗和找到自行车”)通过并行评估多个MC。优化这多个事件是FilterForward的关键贡献。FilterForward没有将MCs设计成对原始像素进行操作,而是从现代对象检测器中获得灵感,并使用了一个共享的基础深度神经网络(DNN)从每个帧中提取一般特征。所有的MCs都从基本的DNN中激活,但它们可能来自不同的层。这样可以将昂贵的像素处理任务分摊到所有MCs上,通过使用边缘节点可用的CPU功率,这样允许同时执行数十个并发的MCs。基础DNN是一种昂贵的开销,但是一旦并发MCs的数量超过一个平衡点,它就可以显著地提高性能。
我们使用两个真实的摄像机数据集进行评估,结果表明,对于满足FilterForward要求的应用程序(在严重的带宽限制下运行,需要高保真数据),我们的体系结构使用的带宽比标准压缩技术少一个数量级(第4.3节)。此外,FilterForward的计算效率很高,当超过3个4 MCs同时运行时,超过了现有轻量级过滤器(Kang et al.,2017)的帧速率,甚至使用50个并发MCs可实现高达6:1的高吞吐量(第4.4节)。最后,MCs比之前工作中使用的基于像素的DNN滤波器精度提高了1.3倍,同时降低了23倍的边际成本(4.5节)。
FilterForward是开源的,请访问:https://github.com/viscloud/ff
2 Background and Challenges(背景与挑战)
在深入研究大型摄像机部署带来的关键挑战之前,本节将概述视频分析。
2.1 Video Analytics(视频分析)
典型的视频分析原型包括:
- 图像分类:根据其最主要的特征(例如,这是一个交集的图像)对整个帧进行分类。
- 对象检测:发现有趣的对象可能只占据视图的一小部分,并对它们进行分类(例如,这个矩形定义了一个包含汽车的区域)。
- 目标跟踪:目的是跨多个帧标记每个目标的位置(例如,该路径绘制行人过马路的进度)。
这些基本概念和其他基本概念构成了更高级分析的基础,如交通监视、行人行为理解和危险检测。
视频分析在大量的数据场景下需要大量的工作量计算(例如,1920 x 1080像素30FPS的视频流在压缩的情况下仍然需要1.5Gb/s的带宽来处理)。完成大规模的视频分析需要大量的计算、内存和存储资源,所以现有的系统常常在云中执行这种处理(使用GPU)(Kang et al., 2017; Zhang et al., 2017)
2.2 Edge-to-cloud Challenges(边缘到云的挑战)
促使FilterForward发展的动力主要包括,远程物联网监控和部署数万或数十万广角固定视角摄像机的智慧城市。在本节中,我们将描述此用例所提出的三个关键挑战。
2.2.1 Limited Bandwidth(有限的带宽)
通过将所有视频流到云中来运行视频分析,这与某些部署的带宽限制相冲突,因为无法上传所有相机数据。由于现代广域网基础设施的物理约束和广泛部署相机的运营成本,每个相机的上行带宽都是有限的。
具体来说,我们考虑大规模部署,每个摄像头接收的带宽分配为每秒几百kb或更少(Public Parking Authority of Pittsburgh, 2018)。作为比较,一个低质量的H. 264编码的1080p(1920 1080像素)流大约是2 Mb/s,比我们可用的上行带宽大一个数量级。然而,这些低质量的数据往往不足以进行准确的分析。现代的4K(3840 x 2160像素)相机可以产生30- 40mb /s,超出上行带宽两个数量级,而且这种差距只会随着8K(7680 x 4320像素)相机变得越来越普遍而扩大。作为一个具体的例子,我们构建了一个校外部署,摄像机安装在十字路口的红绿灯旁边。本地互联网服务提供商对35mb /s的上行链路每月收取400美元的费用,这为我们在尽可能多的相机间共享带宽创造了强大的经济动机(目前,每个上行链路共用8台4K相机)。
对高质量数据的需求加剧了这种带宽差距,因此需要基于边缘的决策,决定将哪些帧发送到数据中心。FilterForward通过只上传与应用程序相关的帧的语义过滤解决了这个问题。
2.2.2 Real-world Video Streams(实时视频流)
在许多监控部署中,摄像机被安装在建筑物或灯柱的高处,并配备广角镜头,以捕捉周围地区的全景。有趣的物体(如行人、车牌、包裹、动物等)占据了画面的一小部分。这对所讨论的视频分析原型(第2.1节)提出了挑战。图像分类将整个图像映射到一个单一的类别,因此城市视点总是被标记为街道或交通,这是有限的用途。目标检测和跟踪是为了从帧中挑选出单独的目标,但通常是在低分辨率图像上操作。(比如,300 × 300像素(Liu et al., 2016))。广角图像的主动下行采样会导致诸如车牌和远处的人等细节消失。为了检测这些细粒度的细节,FilterForward引入了微分类器来处理边缘上的高分辨率图像,避免了由于满足带宽限制所需的抽取而导致的质量下降。
2.2.3 Scalable Multi-tenancy(可伸缩多租户架构)
在真实的部署中,摄像机观察包含不同对象和活动的场景。一个摄像头可以记录行人在人行道上行走,车辆在红绿灯前停下,购物者进入商店;同时记录当前的天气,树上的树叶数量,以及路上是否有雪。不同的应用程序同时对所有这些信息感兴趣,甚至更多。因此,任何边缘过滤方法都必须扩展到多个云应用程序,这些云应用程序应同时关注帧的不相交区域。
考虑到边缘节点有限的计算资源,扩展到多个应用程序自然会带来性能挑战。处理N个应用程序的一种简单方法是同时运行N个完整的DNN。然而,即使是轻量级的DNN也很昂贵。在我们的经验中,在Intel®CPU(而非GPU)上MobileNet (Howard et al., 2017)在512 × 512像素的图像上运行速度约为15帧/秒,同时消耗超过1 GB的内存。即使是轻量级的DNN具有很高的资源需求,因此无法在边缘节点上实时执行多个DNN。因此,要实现可伸缩性,FilterForward是轻量级的MCs简化了每个应用程序的处理,同时DNN在应用程序之间实现了共享冗余计算。
本文的其余部分描述了FilterForward是如何解决上述挑战的:语义过滤抽取视频流以满足带宽限制,在广角视频中检测细粒度细节的新的微型分类器结构,和支持可伸缩的多租户架构的计算重用机制。
3 Designing FilterForward(FilterForward原理)
FilterForward (FF)是一个新颖的视频分析平台,它重用计算为带宽受限的边缘节点提供高精度的多租户架构视频过滤。纯基于边缘的方法将应用程序限制到现场安装的静态计算和存储资源,而仅针对数据访问的分析需要对传输的视频进行大量压缩。FF为应用程序提供了在边缘和云之间分配工作的灵活性,利用边缘的高保真数据来传输到云中以提供相关的视频序列。
3.2 Generating Features(生成特征)
在FF中,微分类器通过将单个参考DNN的中间结果(激活值)作为输入特征图来重用计算,我们将其称为基础DNN。计算基本DNN并生成特征映射的组件称为特征提取器。
正如之前的工作所观察到的(Sharghi et al.;Yeung et al.),激活捕捉的是人类凭直觉希望从图像中提取的信息,如场景中物体的存在和数量,其表现优于手工制作的低层次特征(Razavian et al.,2014;Yue-Hei Ng et al.,2015;Babenko&Lempitsky, 2015)。DNN的第一层(通常是简单的卷积滤波器,如边缘检测器)的激活在视觉上仍然可以识别。后期的激活表示高级概念(例如,眼睛、皮毛等)。由这些活动创建的处理特征图已成功地用于诸如对象区域建议、分割和跟踪,动作分类等任务。(Ren et al., 2015; NodesHariharan et al., 2015; Ma et al., 2015; Bertinetto et al.,2016)
在我们的评估中,我们使用以ImageNet (Russakovsky et al., 2015)为基础的MobileNet (Howard et al.,2017)架构作为基础DNN。MobileNet在精度和计算需求之间提供了一种平衡,这种平衡适合于受约束的边缘节点。我们使用32位(非量化)版本的网络。当然,选择某一个合适的基础DNN不是固定的,我们不认为选择一个特定的网络是这项工作的贡献。评估我们的滤波算法对不同基础DNNs的鲁棒性有待于未来的研究。
特征提取器在解决在真实监控视频中检测小目标的挑战中起着至关重要的作用(第2.2.2节)。FilterForward并没有像传统的基于机器学习的视频分析那样,大幅缩小输入帧,而是检查全分辨率的帧。对于我们的评估,完整的分辨率要么是1920 x 1080像素,要么是2048 x 850像素(第4.1节),而典型的MobileNet输入大小是224 x 224像素,这代表了总的输入数据分别增加了41.3和34.7倍。通过在高分辨率的帧上操作,微小的内容,比如远处的行人,制作和模型特定的汽车细节以及面部的细节都被捕捉到。
然而,随着基本DNN的每一层所做的工作的增加,处理更多的像素会增加大量的计算开销。尽管特征提取是FilterForward中计算最密集的阶段,但它的结果被所有MCs重用,这样可以摊销到每帧,在MCs数量达到盈亏平衡点时,预先增加开销。这种计算重用是实现可伸缩多租户的关键,这是实际监视部署的主要挑战(第2.2.3节)。特征提取网络架构的持续改进,以及硬件加速器的进展(Jouppi et al., 2017; Apple, 2017; intel-movidius;microsoft-project-brainwave)将继续减少过滤器的计算开销。
我们在第4.4节中评估了基本DNN的计算开销。最后,由基本DNN生成的特征图支持FF的准确性和可扩展性。
3.2 Finding Relevant Frames Using Microclassifiers(使用微分类器查找相关帧)
微分类器是一种轻量级的二分类神经网络,它将基础DNN提取的特征图作为输入,输出帧与特定应用程序相关的概率。边缘节点可以在单个摄像机流上运行多个MCs,也可以在多个流上运行较少的MCs。
应用程序开发人员可以选择MC体系结构(我们在3.3节中介绍了几种可能性),并在脱机状态下训练它来检测应用程序所需的内容。为了实现一个MC,开发人员需要提供网络权值和结构特征,以及作为输入的基本DNN层的名称(也可以选择其中的一部分)。
每个微分类器都可以从基础DNN的任何层提取特征图,从而使FilterForward支持不同类型的任务(第2.2.3节)。第3.4节讨论了层的选择过程。
此外,每个MC可以选择裁剪它的特征映射,从而聚焦于帧的特定部分。选择静态子区域(对于每个MC)有助于将FilterForward专门化为广角监视视频(第2.2.2节),因为一些应用程序只对特定区域感兴趣。这样做的一个好处是,它减少了MC的计算负载,并且与输入大小的减少成正比。此外,对MC的空间范围进行约束可以提高准确性(对于某些应用),原因有以下两个
(1)MC必须只考虑帧的相关区域。
(2)通过裁剪,重要的对象变得更加突出。
一个关键的发现是,通过裁剪特性图而不是原始像素,FilterForward保留了同时支持对不同区域感兴趣的MC的能力,这是一个关键的可伸缩性需求。即裁剪MC的特征映射来细化其空间范围是一个可选的局部优化,每个MC独立执行。
FilterForward的主要目标(第2.2.1节)是限制带宽使用的关键。理想情况下,MC将识别应用程序需要在云中处理的所有帧,同时拒绝大量不重要的帧。错误上传尤其有害,因为它们消耗了与数据无关的上传带宽。
FilterForward的主要目标(第2.2.1节)是限制带宽使用的关键。理想情况下,MC将识别应用程序需要在云中处理的所有帧,同时拒绝大量不重要的帧。视频固有的冗余为假阴性提供了安全裕度。误报尤其有害,因为它们消耗了与数据无关的上传带宽。
在后台,边缘节点将原始视频流记录到磁盘上,以便数据中心应用程序能够从边缘节点的本地存储中提取额外的视频(例如,围绕匹配片段的上下文片段)。
正如3.1节中所讨论的,FilterForwards是通过基础DNN在MCs之间共享计算,它是针对现实世界监视部署的多租户需求架构的解决方案(第2.2.3节)。我们在第4.4节和4.5节中指出,在特征图上操作而不是原始像素,可以提供具有竞争力的准确性的微分类器,同时将边际计算成本降低一个数量级。
3.3 Microclassifier Architectures(MC架构)
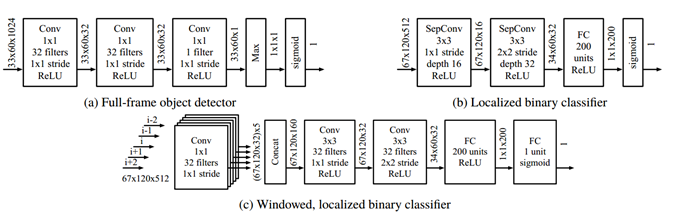
3.3.1 Full-frame Object Detector (图2a)
仿照滑动窗口样式对象探测器,如SSD(Liu et al ., 2016)和Fast R-CNN (Ren et al ., 2015),全帧目标检测器MC在卷积层特征图中每个位置应用一个小的二分类DNN,然后将检测结果聚合起来进行全局预测。这是通过使用1*1卷积的多层来实现的,然后在logits网格上应用max运算符(表示查找多个对象)。这个模型是专门为模式匹配查询设计的,它隐含了平移不变性的假设(即,模型在任何地方都运行相同的模板匹配器),非常适合处理整个广角帧。
3.3.2 Localized Binary Classifier (图2b)
本地化的二进制分类器MC是一个轻量级的卷积神经网络(CNN),它处理空间裁剪的特征图。该体系结构由两个可分离的卷积和一个全连接层组成,用于检测局部区域内的突出物体(比如放大帧的某个区域)。
3.3.3 Windowed, Localized Binary Classifier (图2c)
该体系结构扩展了本地化的二进制分类器MC,将附近的时间上下文包含进来,提高了每帧的准确性。由用户指定包含W帧的临时窗口。给定以F帧为中心的对称W-size窗口的卷积特征映射,带窗口的本地化二进制分类器MC首先对每一帧的特征映射应用1 x 1卷积,然后深度连接结果激活并应用CNN来预测帧F是否是有用的。这种设置允许MC在场景中获取运动线索,这有助于在对象不断移动的任务中实现更高的准确性。初始的单帧1 x 1卷积显著地减少了输入特征图的大小,使得这个更大的架构在边缘节点硬件上计算起来更容易处理。作为一种优化,1 x 1个卷积只计算一次,它们的输出被随后的窗口缓冲和重用,消除了冗余计算。
3.4 Choosing Microclassifier Inputs(选择MC输入)
选择哪一基本DNN层作为每个微分类器的输入对其精度至关重要。CNN层的特征层次结构提供了空间定位和语义信息之间的权衡。太深的话,一个层可能无法观察到小的细节(因为它们已经包含在全局语义分类中)。过浅的层可能在计算上非常昂贵。这是由于早期层激活的规模很大,而且将低级特征转换为分类仍然需要大量的处理。
作为基准,我们手动选择一个图层,并选择一个裁剪区域,基于两种启发式方法。 首先,对于该层,我们尝试匹配我们检测到的对象类的典型大小。例如,要查找1920 × 1080像素中的行人,一个人的平均身高为40像素的视频,我们选择大约已经缩小了20:1–50:1空间的第一层。 在我们的评估中,微分类器从以下MobileNet中提取特征图层:全帧对象检测器使用倒数第二个卷积层(conv5_6 / sep),本地化和窗口化的本地化二进制分类器使用卷积层从网络中间(conv4_2 / sep)开始。 他们的名字特定于我们使用的MobileNet版本(cdwat,2017)。 其次,我们选择基于在应用程序感兴趣的区域上,例如检测人员时的人行横道(4.1节)。
在FF的原型版本中,每个MC均从单个基础DNN层寻找特征,我们约束该特征作物为矩形。合并多个功能层并尝试自由形式和不连续形式作物区域,以及自动选择这些区域参数,是未来工作的挑战。
3.5 From Per-frame Classifications to Events(帧分类映射事件)
首先微型分类器输出每帧二进制分类(即此框架是否相关?),然后FilterForward进行事件检测。 首先,将连续N帧的每个MC的结果累积到一个窗口中。 然后,为了掩盖虚假的误分类,我们对这个窗口应用K- voting,如果窗口中的N个帧中至少有K个是正的检测,则将中间的帧作为检测。对于我们的评估,我们保守地设置了N = 5和K = 2,这以牺牲潜在的假阳性为代价,提供了相当积极的假阴性缓解。得到的经过平滑处理的每帧标签被输入到一个过渡检测器中,该检测器认为每一个被阳性分类的帧的连续段都是一个唯一的事件。每个事件都被分配一个特定于MC的、单调递增的惟一ID,该ID存储在每个帧的元数据中。应用程序使用这些id来确定事件边界。
单个帧可以被多个mc归类为一个有趣事件的一部分。例如,如果frame F是MC A的事件X和MCB的事件Y的一部分,那么F的内部元数据将包含映射(A →X;B→Y)表示它是多个事件的一部分。至于帧本身,它们以用户配置的比特率使用H.264重新编码并流回数据中心。应用程序开发人员为他们的任务指定一个足够高的比特率(这个参数的含义将在4.3节中讨论)。
4 Evaluation(评估)
本节评估FilterForward如何解决第2节中的三个挑战:有限的带宽、实时视频流和可伸缩的多租户架构。我们首先定义我们的数据集和精度度量,然后证明,对于寻找罕见事件的应用程序,FilterForward显著减少了带宽使用。我们证明了FilterForward在普通硬件上实现了高帧率,同时在两个事件检测任务上保持了较高的准确性,而且它的边缘成本低于现有技术。
4.1 Real-world Datasets(真实世界数据集)
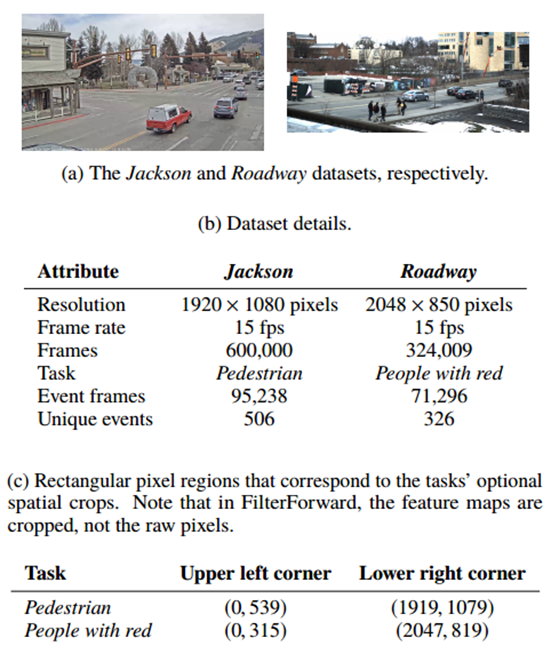
我们使用两个数据集(图3)进行评估,其中显示的场景代表FilterForward目标的真实监视部署。第一个数据集包含Jackson Hole,Wyoming (the Jackson dataset)的交通摄像机部署中捕获的视频。我们连续两天收集了两个6小时的视频,从上午10点到下午4点。然后,我们用标签标注行人出现在人行横道上的时间(行人任务)。这项任务允许我们演示微分类器的空间选择性,希望与未来的流量监控应用程序相关。例如,结合一个简单的红绿灯分类器,用户可以编写复合查询来检测行人。
此外,在我们自己的城市部署中,我们从高质量的相机中收集了第二个数据集,包括两个在中午连续拍摄的城市街道(the Roadway dataset)的三个小时视频。我们在六个小时的数据中标注了穿红色衣服的行人或拿红色包裹的人(the People with red task)。对于这两个数据集,第一个数据集是用来训练,第二个是用来测试的。
表3c详细列出了这些任务的可选空间作物对应的像素区域。对于行人任务,我们选择了框架的下半部分,因为树和天空是不必要的。对于the People with red task,我们选择街道和人行道区域(59%的画面)。FilterForward裁剪的是由基础DNN生成的特征图,而不是原始像素,因此表3c中的坐标是根据特征图的尺寸重新调整的。这些作物是否有效将在下面的每个实验基础上进行描述。MCs从中提取特征的基本DNN中间层在3.4节中进行了描述。
大多数分类指标都是以每帧为基础的。因为FilterForward是以事件为中心的,所以我们从最近的工作中采用了一个修改后的recall matrix,它是为跨多个帧的事件设计的(Lee et al., 2018)。对于一个事件i,可以产生$\text {EventRecall}{i}$(这是一个衡量标准),它有两个成功度标准: $\text {Existence}{i}$ 表示在某事件中检测至少一个帧时,这种情况发生的越多,其奖励值越高,而 $\text {Overlap}{i}$ 奖励从事件中检测越来越多的帧。Ri和Pi分别是真实情况和预测事件。
$$
\begin{aligned}
\text {Existence}{i} &=\left{\begin{array}{ll}
{1} & {\text { if detect any frame in event } i} \
{0} & {\text { otherwise }}
\end{array}\right.\
\text { Overlap }{i} &=\sum{j} \frac{| \text { Intersect }\left(R_{i}, P_{i}\right) |}{\left|R_{i}\right|} \
\text {EventRecall}{i} &=\alpha \times \text {Existence}{i}+\beta \times \text { Overlap}_{i}
\end{aligned}
$$
我们选择α= 0.9和β= 0.1,这样更重视每一个事件。对于监视环境中的实时事件检测,我们认为不丢失事件比捕获事件中的所有帧更重要。如果应用程序从一个事件接收到至少一个帧,那么它可以在事件之间进行优先级排序时请求获取额外的帧。
另一方面,我们保留了精度的标准定义:准确预测帧的比例(即$\frac{ \text { correctly detected }}{\text { total } \text { detected }}$),对于FilterForward,精度决定了用于发送相关帧的带宽比例。精度为1.0意味着所有带宽都用来发送有用的正帧。我们将标准精度与我们修改后的事件recall定义相结合,来计算一个事件F1得分,即精度和recall的调和平均值,在整个评估过程中使用。一个直观的方法来理解F1分数是作为一个测量端到端事件检测精度。
4.3 Saving Wide Area Bandwidth(节约广域网带宽)
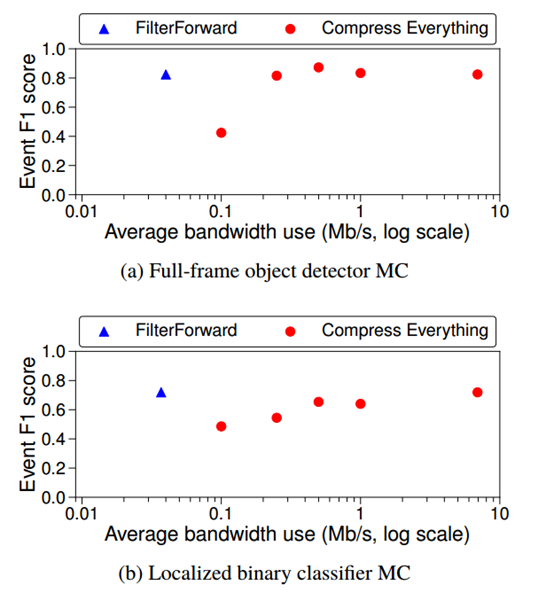
首先,我们证明FilterForward实现了它的主要目标,即节省边缘到云的带宽(第2.2.1节)。具体来说,使用FF在边缘上进行过滤要比大量压缩和上传整个流节省6.3-13倍的带宽。
图4显示了两种MC架构的平均带宽使用和F1得分。在这个图中,我们评估了从边缘上传视频的两种技术:FilterForward对应于在边缘上运行FF,在原始流上,然后压缩选择的帧进行上传,Compress everything表示上传整个流,压缩到低比特率,然后在云中运行FF。
(1)降低分辨率是不可行的,因为这样做会极大地破坏小细节;
(2)时间采样是不可行的,因为减少几帧并不会节省成比例的带宽(视频压缩得很好,所以每一帧不会增加太多开销),而且任意减少多帧会掩盖短事件。
使用全帧对象检测器(图4a)和本地化的二进制分类器(图4b) MCs对边缘进行过滤,与上传完整流相比,MCs分别减少了6.3倍和13倍的带宽使用。将匹配的帧分别重新编码到250kb /s和500kb /s并上传。对于任务和MC的组合,这些比特率是足够好的。但是,需要注意的是,FF的带宽节省与所选的上传比特率无关。无论应用程序开发人员为他们的任务选择什么样的上传比特率,FF都能够通过通过丢弃不相关的帧来更有效地利用带宽。即,FF允许用户将有限的带宽资源集中在最重要的帧上,从而以尽可能高的质量将这些帧交付给数据中心,而不是在所有帧上均匀地分配可用带宽。
当然,当FF的帧数下降时,这取决于MCs正在搜索的事件是否常见。聚合检测频率越低,FF节省的带宽越多。在图4中,本地化的二进制分类器MC节省了更多的带宽(例如,丢失了更多的帧)。因为它有更多的漏报(它错过了一些事件)。
在准确性方面,与将整个流大量压缩相比,全帧对象检测器和局部二进制分类器MC分别将事件F1得分提高了1.5倍和1.9倍,这展示了它处理高保真数据的价值:当使用相似数量的带宽时,FF比上传完整流具有更高的准确性,因为在边缘上过滤原始数据使FF可以访问压缩破坏的细节。 实际上,FF将发送原始视频的准确性与节省大量压缩的带宽结合在了一起。
4.4 End-to-end Performance Scalability(端到端可伸缩性)
FilterForward将性能可扩展性视为一流的设计目标(第2.2.3节)。 为了展示微分类器的低边际成本,我们将两种替代过滤技术进行了比较:
(1)运行完整DNN(MobileNet)的多个实例,
(2)训练专门的像素级分类器。 专用分类器由于处理原始像素而被称为离散分类器(DC),类似于NoScope(Kang等人,2017)中使用的技术(在第5.2.1节中进一步讨论)。 DC比通用图像分类DNN(MobileNet)速度快,但比MC贵。 第4.5节提供了与DC更加详细的成本和准确性比较。 FilterForward,DNN和DC都将在全分辨率帧上运行,这些实验的分辨率为1920×1080像素。
我们构建了几个在1亿到25亿倍多重adds之间的DCs,改变了卷积层数(2-4)、内核数(16-64)、步长(1-3)、池化层数(0-2)和卷积类型(标准或可分离)。我们将内核大小固定为3。我们从帕累托边界的准确性和成本中获得了一个代表性的例子的结果。
所有的性能实验都是在台式机上进行的,使用的是Intel Core i7-6700K四核CPU和32gb RAM(只使用CPU,不是GPU,也不是多个CPU集成的集群)。根据我们的经验,这个CPU是安装在灯柱上的边缘节点的代表,但是我们希望未来的部署也包含GPU或DNN硬件加速器。我们使用为Intel-cpu (Intel)优化的Caffe深度学习框架(Caffe)的一个版本来执行基本的DNN,并使用Intel-Math内核库来执行深度神经网络(intel -mkl- dnn)。我们使用TensorFlow执行MCs和DCs (Abadi et al.,2016)。我们在短参数扫描的基础上,独立设置完整DNNs、DCs和MCs的神经网络批处理大小。为了减少CPU争用,我们使用端到端流控制来保证FilterForward的基本DNN和MCs是分阶段执行的(而不是流水线),这样Caffe和TensorFlow就不会争夺核心。评估视频是H.264压缩的,驻留在磁盘上,并且总是被写回磁盘(为了模拟对延迟上传的完整流进行归档),因此所有性能实验都隐含地包含了磁盘读/写和H.264解码。任何时候都不会出现磁盘访问或解码瓶颈。由于我们的测试软件堆栈没有经过大量优化,所以性能度量的重要性不如不同架构如何伸缩的趋势重要。
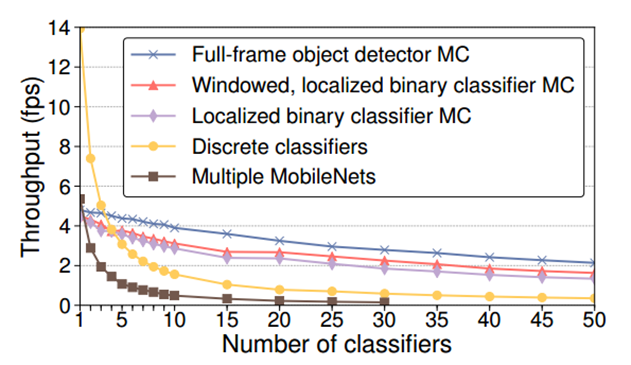
图5比较了FilterForward的三种MC架构的过滤吞吐量与多个完整的MobileNet DNNs和noscope风格的离散分类器的过滤吞吐量相比。在只有一个分类器的情况下,FilterForward过程以DCs 0.32-0.34倍的速度和MobileNets 0.83-0.90倍的速度进行帧处理。如果有20个分类器,这已经上升到于DCs相比快3倍-4倍的速度。通过50个分类器,FilterForward可以将速度提高6.1倍。直观地说,只使用一个过滤任务,使用MobileNet直接获得比FilterForward更高的吞吐量,因为后者需要特征提取和数据移动开销。根据两个分类器,这些开销并不重要。另一方面,当分类器的数量较少时,DCs具有更高的吞吐量,因为它们不需要支付运行昂贵的完整DNN的开销。
然而,由于每个DC必须计算从像素到决策的完整转换,他们做了很多冗余的工作。通过共享计算和分摊其基本DNN的成本,FilterForward在使用3 - 4个分类器时速度更快。运行多个mobilenet虽然简单,但是从吞吐量的角度来看,它从来都不是最优的,并且超过30个分类器时存在内存不足的问题。最后,对于具有大量筛选任务的用例,FilterForward提供的吞吐量比现有技术高得多。
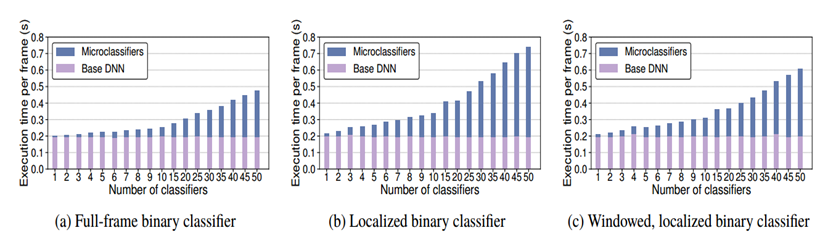
4.5 Microclassifier Cost and Accuracy(微分选机的成本和精度)
最后,我们证明因为它们是在特征图上操作的,与离散分类器相比,FilterForward的微分类器具有较低的边际计算成本,在真实世界数据集上的准确性更高(第2.2.2节)。
对于DNN来说,乘-加(multiply-adds/MAdd)是衡量计算开销优秀标准。给定一个的特征图大小为HxM,深度为M,那么MAdd的在一个全连接带有N个神经单元的层中为:NxHxWxM.对于相同的特征图,在一个带有F滤波的KxK卷积层大小且幅度为S,MAdd的数量为:$\frac{H}{S} \times \frac{W}{S} \times M \times K^{2} \times F$。卷积层的成本可以通过使用可分离或分解的卷积(内核被分成深度卷积和点态卷积)来降低,但会在一定程度上降低精度。在参数相同的可分卷积层中,MAdd的个数为:$\frac{H}{S} \times \frac{W}{S} \times M \times\left(K^{2}+F\right)$。记得FilterForward摄取全分辨率的视频,所以在我们的实验中,增加的倍数比典型的输入大小要大得多,比如224 x 224像素。
图7比较了两个微分类器的准确性(事件F1得分)和边际计算成本(MAdd)与两个数据集的离散分类器的精度。与DCs相比,在Jackson dataset上,FilterForward的MC的精确度可达1.3倍,降低成本23倍,在Roadway dataset上精度可以提高1.1倍,可降低11倍的成本。这种边际计算成本的数量级节省是由于MCs在特征图上而不是在像素上运行,这意味着他们有更少的工作要做(将特征转换为分类比转换像素更简单)。当然,需要权衡的是,MC必须预先牺牲前期基础DNN带来的成本。
我们认为,在图7中,与DC相比,精度略有提高是使用更复杂的网络进行像素处理的副产品。 DC必须在准确性和成本之间保持一个良好的平衡:与MobileNet等完整的多类DNN相比,要保持轻量级,它们会牺牲复杂性。通过摊销其所有MC上的像素处理,FF允许用户运行更强大的特征提取网络,因此与使用DC相比,FF可以提取更高质量的特征,这些特征是进行附加分析的更好基础。
本节概述适用于2.2节中提出的三个挑战的相关工作(有限带宽、实时视频流和可伸缩的多租户架构)
5.1 Conventional Machine Learning Approaches
重用计算的传统ML技术提高了可伸缩性,但其刚性牺牲了准确性。转移学习利用经过图像分类和目标检测训练的DNNs识别出能够很好地转移到特定任务的一般特征,从而加速多应用训练和推理(Donahue et al.,2014;Yosinski et al.,2014)。在推理过程中,通过运行一个基本的DNN完成并提取其最后一层的激活作为特征向量来转移学习份额计算,然后由多个专门的分类器使用(每个应用程序一个)(Pakha et al.,2018)。最近的工作允许特定于应用程序的DNN与基础DNN共享多个层(Jiang et al.,2018a),类似于我们的微分类器可以从任何一层过滤器中提取出s基础DNN。然而,传统的转移学习对小对象的准确性较差,因为它保留了原DNN结构的再训练层。尽管这些方法在计算上很有效,但它们并不适合真实的视频流。
多任务学习(Caruana, 1998)提供了一种跨模型共享计算的有效方法,但在添加新任务时必须对所有模型进行重新训练。这种再培训开销使得多任务学习不适合真实的部署,因为任务经常被添加和删除。
5.2 Filtering-based Approaches(基于过滤的方法)
通过丢弃不相关的帧来过滤视频,可以减少计算和传输负载(Kang et al., 2017;Pakha et al.,2018;Wang et al.,2018)。过滤的一种方法是使用一个逐步精确和昂贵的检测器级联,在最便宜的模型上一直执行到停止,这样可以产生一个高可信度的预测。这是一种用于优化快速路径的常用技术,其中大多数帧可以在级联开始时丢弃。在这个领域的早期工作包括(Viola & Jones, 2001),该方法引入了基于传统计算机视觉特征的检测器级联,并引入了注意机制来修剪特征空间和提高吞吐量。FilterForward以这个想法为基础,但专门用于探测监视视频中的小目标。与前面提到的注意机制类似,FF包含一个可选的优化,其中一个微分类器可以从空间上裁剪它的特征映射来聚焦于一个特定的区域(以提高准确性)并减少模型的复杂性(以节省计算)。
5.2.1 Saving Compute During Bulk Analytics(在批量分析期间保存计算)
最近的工作已经应用过滤级联来减少批量视频分析的计算负载。NoScope (Kang et al.,2017)将与参考图像或前一帧的像素级差异不满足阈值的帧放入级联。NoScope首先评估便宜的、特定于任务的、像素级的CNNs(例如,一个订制的“雪德兰马”的二进制分类器),我们称之为离散分类器,并且当廉价CNN的信心低于阈值时,才应用昂贵的CNN(例如,YOLO9000)(Farhadi, 2016))。离散分类器类似于我们的mc,除了它们操作的是原始像素。在FilterForward中,基础DNN对所有MCs的像素处理进行摊销,在不牺牲精度的情况下降低每个分类器的边际成本。我们在4.4节和4.5节中比较了我们的MCs和NoScope的离散分类器的吞吐量和准确性。
以前的系统通常是在高度精选的数据集上进行评估的,这些数据集编排使得视频分析更容易。 例如,对NoScope(Kang等人,2017)的评估是针对已裁剪到感兴趣的狭窄区域(对象通常占据帧的大部分)的视频进行的。 以这种方式放大对象使分析既容易(因为对象更加突出)又便宜(因为可以降低DNN输入的分辨率)。 但是,以这种方式修改数据有悖于我们处理广角监控视频的目标。 FilterForward支持类似的裁剪技术,但这对其设计并不重要。
Focus (Hsieh et al.,2018)将处理时间分为获取时间和查询时间,使用廉价的CNNs和集群来预先构建一个近似的索引,极大地加快了离线查询的速度。Focus 的 ingest CNN在概念上类似于FilterForward 的base DNN,它们都生成关于每个帧的语义信息,用于未来的处理,但是我们使用的feature map而不是top类,这样做使用更加广泛。在索引中存储每帧元数据的概念适用于FilterForward,这是未来工作的一个有趣方向,
NoScope和Focus都假设可以将所有视频流传输到资源丰富的数据中心。这对于他们的算法来说不是基础,但是将两个系统的组件推到边缘会引入额外的计算约束。FilterForward的一个基本前提是上传所有的视频是不可行的,因此我们的设计建立在计算共享的基础上,使边缘节点能够支持许多并发应用程序。
5.2.2 Saving Bandwidth on Constrained Edge Nodes(在边缘节点上节约带宽)
与FilterForward类似,其他人也解决了在边缘生成的视频上实时运行ML工作负载的挑战。(Pakha et al.,2018)和(Wang et al.,2018)都将计算推到了边缘,以确定哪些帧对于云中的重量级分析来说是无趣的。
(Pakha et al.,2018)仅在相关对象出现时使用采样和叠加编码发送帧,然后使用尽可能低的质量。虽然这项工作节省了大量带宽,但edge和云之间的迭代通信限制了它的吞吐量。
(Wang et al.,2018)研究了使用4G LTE蜂窝网络从一群自主无人机实时卸载视频的高带宽限制用例。与FilterForward类似,该系统使用轻量级的DNN(例如MobileNet),运行在边缘(这里是在无人机上),并结合轻量级的分类器(它们使用支持向量机(SVMs))来早期指示一个帧是否是我们的感兴趣的帧。这些支持向量机在原理上类似于我们的微分类器,但其总是从基础DNN的最终池层提取的激活,并且比MCs浅得多,这意味着它们的学习能力较低,准确性较差。
此外,这两个系统都没有针对多租户架构进行优化。FilterForward的设计将查询可伸缩性作为首要考虑,并且可以运行几十个并发的微分类器。(Pakha et al., 2018)和(Wang et al.,2018)都专注于摄像头移动的流,而FilterForward考虑的是固定的监控摄像头。在全局运动较少的流上操作使FilterForward具有优势,因为它更容易为这些流训练分类器,并且不变像素的较大比例使这些流更容易压缩。
5.3.3 Resource Scheduling for Video Pipelines(视频管道的资源调度)
资源管理对于实际的视频分析来说是至关重要的,因为应用程序经常会相互冲突,即最大化它们的整体利益和满足性能约束。例如,VideoStorm (Zhang et al., 2017)调整查询质量以最大化综合效用,使用高效的调度来利用离线质量和资源配置文件。LAVEA (Yi et al.,2017)跨边缘节点和客户端(如手机)放置任务,这样可以减少视频分析的延迟。DeepDecision (Ran et al.,2018)将视频处理中的资源调度表示为一个组合优化问题。随着场景内容的变化,变色龙(Jiang et al.,2018b)动态调整视频处理管道的超参数,使用时间和空间(例如邻近的摄像头)的相关性来修改优化搜索空间。
大部分的这些调度工作都是对FilterForward的补充,FilterForward与它们有一个相似的动机,即平衡准确性和吞吐量,但主要关注具有有限网络带宽的边缘节点。与之前的调度工作只调整视频比特率、分辨率和DNN模型选择等常规控制不同,FilterForward的计算共享直接提高了运行在同一边缘节点上的多个过滤器的计算效率。
6 Conclusion(结论)
扩展实时广域视频分析对带宽有限、计算受限的摄像机部署提出了挑战。本文介绍了FilterForward,一种新的边缘过滤架构,它使用轻量级的、每个应用程序的微分类器来识别要上传的相关视频片段。我们证明了FF在不牺牲精度的情况下,将带宽使用降低了一个数量级,同时将吞吐量扩展到比现有方法高6倍的水平。然而,尽管本文从节省边缘带宽的角度描述了FilterForward,但我们认为,在基于机器学习的云分析中,我们的可伸缩早期丢弃算法也是一种省略不必要计算的可行方法。我们认为FilterForward的计算共享和边到云的混合设计超越了视频处理,为ML应用程序在受限环境中提供了有用的构建块。
FilterForward是开源的,请访问https://github.com/viscloud/ff
Acknowledgments(鸣谢)
我们赞赏SysML`19项目委员会和我们在卡内基梅隆大学和英特尔实验室的同事的真知灼见。这项工作由英特尔通过英特尔视觉云系统科学技术中心(ISTC-VCS)支持。
Reference
Abadi, M., Barham, P., Chen, J., Chen, Z., Davis, A., Dean,J., Devin, M., Ghemawat, S., Irving, G., Isard, M., Kudlur,M., Levenberg, J., Monga, R., Moore, S., Murray, D. G.,Steiner, B., Tucker, P., Vasudevan, V., Warden, P., Wicke,M., Yu, Y., and Zheng, X. TensorFlow: A system for large-scale machine learning. In Proc. 12th USENIX OSDI, Savannah, GA, November 2016.
Apple. The future is here: iPhone X. https://www.apple.com/newsroom/2017/09/the-future-is-here-iphone-x/, 2017.
Babenko, A. and Lempitsky, V. Aggregating local deep features for image retrieval. In The IEEE International Conference on Computer Vision (ICCV), December 2015.
Bertinetto, L., Valmadre, J., Henriques, J. F., Vedaldi, A.,and Torr, P. H. Fully-convolutional siamese networks for object tracking. In European Conference on Computer Vision, pp. 850–865. Springer, 2016.
caffe. Caffe. http://caffe.berkeleyvision.org/,2017.
Canel, C., Kim, T., Zhou, G., Li, C., Lim, H., Andersen, D. G., Kaminsky, M., and Dulloor, S. R. Scaling video analytics on constrained edge nodes. In Proceedings of the 2nd SysML Conference (SysML ‘19), Palo Alto, CA,2019.
Caruana, R. Multitask learning. In Learning to learn, pp.95–133. Springer, 1998.
cdwat. MobileNet-Caffe. https://github.com/cdwat/MobileNet-Caffe, 2017.
Donahue, J., Jia, Y., Vinyals, O., Hoffman, J., Zhang, N.,Tzeng, E., and Darrell, T. Decaf: A deep convolutional activation feature for generic visual recognition. In International conference on machine learning, pp. 647–655,2014.
FCC. 2016 BROADBAND PROGRESS REPORT. 2016.Google Wireless Internet. Google’s Excellent Plan To Bring Wireless Internet To Developing Countries. https://www.forbes.com/sites/timworstall/2013/05/25/googles-excellent-plan-to-bringwireless-internet-to-developing-countries/,2013.
Hariharan, B., Arbeláez, P., Girshick, R., and Malik, J.Hypercolumns for object segmentation and fine-grained localization. In Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition, pp. 447–456,2015.
Howard, A. G., Zhu, M., Chen, B., Kalenichenko, D.,Wang, W., Weyand, T., Andreetto, M., and Adam, H.Mobilenets: Efficient convolutional neural networks for mobile vision applications. CoRR, abs/1704.04861, 2017.
URL http://arxiv.org/abs/1704.04861.
Hsieh, K., Ananthanarayanan, G., Bodik, P., Venkataraman,S., Bahl, P., Philipose, M., Gibbons, P. B., and Mutlu, O.Focus: Querying large video datasets with low latency and low cost. In 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), pp. 269–286, Carlsbad, CA, 2018. USENIX Association. ISBN978-1-931971-47-8.
URL https://www.usenix.org/conference/osdi18/presentation/hsieh.
IHS. Top Video Surveillance Trends for 2017.https://cdn.ihs.com/www/pdf/TEC-VideoSurveillance-Trends.pdf, 2017.
Intel. Intel distribution of caffe. https://github.com/intel/caffe
intel-mkl-dnn. Intel Math Kernel Library for Deep Neural Networks. https://01.org/mkl-dnn, 2018.
intel-movidius. Intel Movidius Neural Compute Stick. https://developer.movidius.com/, 2018.
ITU/UNESCO Broadband Commission for Sustainable Development. The State of Broadband: Broadband catalyzing sustainable development. 2017.
Jiang, A., Wong, D. L.-K., Canel, C., Misra, I., Kaminsky, M., Kozuch, M., Pillai, P., Andersen, D. G., and Ganger,G. R. Mainstream: Dynamic stem-sharing for multi-tenant
video processing. In 2018 USENIX Annual Technical Conference (USENIX ATC 18), 2018a
Jiang, J., Ananthanarayanan, G., Bodik, P., Sen, S., and Stoica, I. Chameleon: Scalable adaptation of video analytics. In Proceedings of the 2018 Conference of the ACM Special Interest Group on Data Communication,SIGCOMM ’18, pp. 253–266, New York, NY, USA,2018b. ACM. ISBN 978-1-4503-5567-4.
doi: 10.1145/3230543.3230574. URL http://doi.acm.org/10.1145/3230543.3230574
Jouppi, N. P., Young, C., Patil, N., Patterson, D., Agrawal,G., Bajwa, R., et al. In-datacenter performance analysis of a tensor processing unit. CoRR, abs/1704.04760, 2017.URL http://arxiv.org/abs/1704.04760.
Kang, D., Emmons, J., Abuzaid, F., Bailis, P., and Zaharia,M. Noscope: Optimizing deep cnn-based queries over video streams at scale. PVLDB, 10(11):1586–1597, 2017
Lee, T. J., Gottschlich, J., Tatbul, N., Metcalf, E., and Zdonik, S. Precision and recall for range-based anomaly detection. In Proc. SysML Conference, Stanford, CA, February 2018.
Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu,C.-Y., and Berg, A. C. Ssd: Single shot multibox detector.In European conference on computer vision, pp. 21–37.
Springer, 2016
Ma, C., Huang, J.-B., Yang, X., and Yang, M.-H. Hierarchical convolutional features for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision, pp. 3074–3082, 2015.
microsoft-project-brainwave. Microsoft unveils Project Brainwave for real-time AI. https://www.microsoft.com/en-us/research/blog/microsoft-unveils-project-brainwave/, 2018.
Pakha, C., Chowdhery, A., and Jiang, J. Reinventing video streaming for distributed vision analytics. In 10th USENIX Workshop on Hot Topics in Cloud Computing
(HotCloud 18), Boston, MA, 2018. USENIX Association.
URL:https://www.usenix.org/conference/hotcloud18/presentation/pakha.
Public Parking Authority of Pittsburgh. Rfp for unified security camera system. http://apps.pittsburghpa.gov/redtail/images/3780_RFP_FOR_UNIFIED_SECURITY_CAMERA_SYSTEM_9.20.18.pdf, 2018.
Ran, X., Chen, H., Zhu, X., Liu, Z., and Chen, J. DeepDecision: A mobile deep learning framework for edge video analytics. In Proc. INFOCOM, 2018.
Razavian, A. S., Azizpour, H., Sullivan, J., and Carlsson,S. Cnn features off-the-shelf: An astounding baseline for recognition. In Proceedings of the 2014 IEEE Conference
on Computer Vision and Pattern Recognition Workshops,CVPRW ’14, 2014.
Redmon, J. and Farhadi, A. YOLO9000: better, faster, stronger. CoRR, abs/1612.08242, 2016. URL http://arxiv.org/abs/1612.08242
Ren, S., He, K., Girshick, R., and Sun, J. Faster r-cnn:Towards real-time object detection with region proposal networks. In Advances in neural information processing
systems, pp. 91–99, 2015.
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S.,Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein,M., Berg, A. C., and Fei-Fei, L. ImageNet large scale
visual recognition challenge. International Journal of Computer Vision (IJCV), 115(3):211–252, 2015.
Sharghi, A., Laurel, J. S., and Gong, B. Query-focused video summarization: Dataset, evaluation, and A memory network based approach. In 2017 IEEE Conference on
Computer Vision and Pattern Recognition, CVPR 2017,CVPR 2017.
Sharma, S., Kiros, R., and Salakhutdinov, R. Action recognition using visual attention. arXiv preprint arXiv:1511.04119, 2015.
Viola, P. and Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Conference on Computer Vision and Pattern
Recognition (CVPR 2001), 2001.
Wang, J., Feng, Z., Chen, Z., George, S., Bala, M., Pillai, P.,Yang, S.-W., and Satyanarayanan, M. Bandwidth-efficient live video analytics for drones via edge computing. In Proceedings of the Third ACM/IEEE Symposium on Edge Computing (SEC 2018), Bellevue, WA, 2018.
Yeung, S., Russakovsky, O., Mori, G., and Fei-Fei, L. Endto-end learning of action detection from frame glimpses in videos. In 2016 IEEE Conference on Computer Vision
and Pattern Recognition, CVPR 2016, CVPR 2016.
Yi, S., Hao, Z., Zhang, Q., Zhang, Q., Shi, W., and Li,Q. LAVEA: Latency-aware video analytics on edge computing platform. In 2017 IEEE 37th International Conference on Distributed Computing Systems (ICDCS),2017.
Yosinski, J., Clune, J., Bengio, Y., and Lipson, H. How transferable are features in deep neural networks? In Advances in neural information processing systems, pp.3320–3328, 2014.
Yue-Hei Ng, J., Yang, F., and Davis, L. S. Exploiting local features from deep networks for image retrieval. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, June 2015.
Zhang, H., Ananthanarayanan, G., Bodik, P., Philipose, M.,Bahl, P., and Freedman, M. J. Live video analytics at scale with approximation and delay-tolerance. In Proc.14th USENIX NSDI, Boston, MA, March 2017.